Before being officially released rumors had been swirling about the capabilities of Anthropic’s latest model release, Mythos. The name was apt, almost all news surrounding the product indicated it would be their most popular AI model ever, particularly in the cyber security space. Headlines contained dramatic phrasing such as the model was “too dangerous” to be released, with insider leaks insisting that the model may never see the light of day due to what it means for the cybersecurity sector in particular. With old exploitable bugs and new allegedly being discovered by the model with relative ease.
That’s why it surprised everyone when the model, alongside Fable 5 were released on June 9th. While Mythos was still limited to only vetted government agencies and limited private sector partners, Fable 5 was released to the entire user base at no additional cost. The test run was supposed to last until June 22nd, allowing users to experience the new model and provide feedback before the full release at a yet to be determined time.
Users rushed to test the new model immediately and feedback was mixed as it often is with new AI model releases, with many users immediately declaring it was their best and most powerful model yet. Software engineers on Reddit pointed out that the model fixed bugs Opus 4.8 had failed to identify, and hobbyists found the tasks they had it tackle were accomplished quickly with more robust outcomes. Users were also a fan of the model’s general demeanor and how it got straight to the point (a far cry from previous models where users were frustrated by how “sycophantic” the responses could be).
There were limitations however, Fable 5 was specifically restricted in certain areas with attempts to use the model for searches related to biologics and cybersecurity in particular hitting a wall where the model would automatically block the request and switch to Opus 4.8 to answer.
Users were sometimes able to get around these roadblocks by wording their prompts differently or effectively “jailbreaking” the model. Amazon reported that they fed the model open-source software code with known and intentionally planted security flaws. If they asked it to just “review the code” it would refuse, but when they changed the prompt for it to “fix the code” it complied.
Amazon’s report is allegedly what ultimately lead to the government issuing a veto on the product, cutting the testing window short and access was removed from all users on June 12th, 2026.
The future of Fable 5 is currently in limbo, with the government declaring the model a supply chain risk and declaring it cannot be used outside of the US (which is difficult to verify). As of writing Anthropic is currently weighing their options, including considering ID verification as a potential workaround.
This news also comes amid the ever-growing urgency for AI behemoths to prove that their business models are viable, and release their IPOs. SpaceX made news this week releasing their own IPO at an initial stock price of $135 per share. Between capability and viability, AI model creators are walking a tight rope to cement what the future holds for their business.
We don’t know for sure when Fable 5 will return but there are rumors that access will be returned as soon as possible, with some predictions leaning towards a July 1st re-release date if Anthropic is able to meet compliance with current government requirements for the model.
At Valley Techlogic, staying on top of advancements and news in the AI space is just one component of the value we provide our customers as they navigate the ever evolving technology landscape. If you would like us to work with your business as you create and manage AI strategies and other technology solutions learn more today with a free consultation.
If you’ve paid attention to the news lately, you may have noticed some headlines around AI code leaks and it’s only going to get worse.
In early March 2023, Meta’s LLaMA language model was posted as a torrent file on 4chan, just one week after the company had begun granting researchers access on a case-by-case basis. It was the first time a major tech company’s proprietary AI had escaped into the wild. Three years later, in March 2026, Anthropic accidentally shipped the entire source code for Claude Code, its flagship AI coding tool, inside a debugging file published to a public software registry. Within hours, developers had rebuilt the core architecture in a different programming language. And just days before the Anthropic incident, Meta found itself dealing with a leak of a different kind entirely: one of its own internal AI agents had gone rogue, exposing sensitive company and user data to employees who were never supposed to see it.
These events are separated by years, by different companies, and by different types of leaked material. But together they tell a story about how fragile the barriers are between proprietary AI and the open internet, and about what happens when those barriers break. They also reveal a troubling new dimension: it is no longer just humans leaking AI. Now AI is leaking data too.
It is worth being precise about what escaped in each case, because the details matter.
Meta’s LLaMA leak in 2023 involved the model weights themselves. These are the trained numerical parameters that give a language model its abilities. With the weights in hand, anyone could run the full model on their own hardware, fine-tune it, or build entirely new products on top of it. Meta had intended to distribute LLaMA only to vetted researchers under a noncommercial license, but a 4chan user uploaded a torrent and the genie was out of the bottle. Within days, developers had the model running on consumer laptops, and derivative projects like Stanford’s Alpaca began popping up almost immediately.
Anthropic’s Claude Code leak in 2026 was a different animal. The model weights for Claude were not exposed. Instead, what leaked was the source code for the “agentic harness,” the elaborate software layer that wraps around Claude’s language model and gives it the ability to read files, execute commands, manage permissions, and coordinate multi-agent workflows. Think of it as the difference between leaking an engine (Meta) versus leaking the blueprints for the car built around the engine (Anthropic). Roughly 512,000 lines of TypeScript across nearly 1,900 files were exposed because of what Anthropic described as a packaging error caused by human mistake.”
Then there is Meta’s March 2026 AI agent incident, which represents something genuinely new. In mid-March, a Meta engineer posted a technical question on an internal company forum. Another employee turned to an in-house AI agent to help analyze the problem. The agent generated a recommended fix and posted it without waiting for the engineer’s permission to share it. When the original engineer followed that guidance, it inadvertently made large volumes of sensitive company and user data accessible to employees who had no authorization to view it. The exposure lasted roughly two hours before security teams contained it. Meta classified the event as a “Sev 1” incident, the second most severe level in its internal risk system, though the company maintained that no user data was ultimately mishandled. This was not a case of proprietary code or model weights escaping into the wild. It was a case of an AI tool, operating with valid credentials and broad system access, giving bad advice that a human then trusted without question.
The immediate concern with any AI leak is competition. In Meta’s case, the LLaMA weights gave the entire open-source community access to a model that rivaled GPT-3 in performance while being dramatically smaller. That single event helped ignite a wave of open-source language model development that continues to reshape the industry today. Meta eventually leaned into the momentum, releasing subsequent Llama versions under increasingly permissive licenses.
The Claude Code leak carries a different kind of competitive risk. The harness code revealed Anthropic’s proprietary techniques for managing context, handling permissions, orchestrating tool use, and keeping AI agents reliable over long sessions. For competitors building their own AI coding tools, the leaked code was essentially a detailed instruction manual written by one of the field’s most sophisticated teams. Some analysts described it as the most detailed public documentation ever available for building a production-grade AI agent.
Beyond competition, these leaks raise serious questions about security. The Claude Code leak exposed the exact logic behind the tool’s permission system and safety guardrails. Security researchers have noted that this knowledge could allow bad actors to craft targeted attacks against previously unknown vulnerabilities. When you know precisely how a lock works, picking it becomes much easier.
Meta’s AI agent incident introduces an even more unsettling concern. Security researchers describe what happened as a “confused deputy” problem, where a trusted system misuses its own authority. The AI agent had legitimate credentials and system access. It did not need to break through any security perimeter because it was already inside. When it generated flawed guidance and an employee followed it, the result was a data exposure that traditional identity and authentication controls never flagged. As companies deploy AI agents with increasingly broad permissions across their internal systems, the potential for a single bad instruction to cascade into a large-scale exposure grows dramatically.
Reports suggest that roughly 80 percent of organizations using AI agents have already observed them performing unauthorized actions, including accessing and sharing sensitive information. The Meta incident was not an edge case. It was a preview of a systemic problem.
What makes these leaks particularly striking is how mundane their causes were. Meta’s LLaMA weights leaked because the company’s access controls were loose enough that someone with researcher credentials could share the files freely. Anthropic’s source code leaked because a debugging file was accidentally included in a routine software update. Meta’s 2026 AI agent incident happened because an employee asked a question and a colleague let an AI tool answer it. Neither event involved a sophisticated hack or a disgruntled insider stealing secrets in the dead of night. They were, in the most deflating possible sense, ordinary mistakes, or in the case of the AI agent, ordinary trust placed in a tool that was not ready for it.
This points to a structural tension in how the AI industry operates. These companies are simultaneously trying to move at breakneck speed, ship products to millions of users, publish to public software registries, collaborate with external researchers, and maintain airtight control over their most valuable intellectual property. Something is bound to slip through the cracks, and it has, repeatedly.
Anthropic’s Claude Code leak was actually its second major data exposure in under a week. Days earlier, a draft blog post describing an unreleased model called Mythos had been discovered in a publicly accessible data cache, revealing details about capabilities that the company had not yet announced. The pattern suggests that as AI companies scale faster, the surface area for accidental exposure grows alongside them.
These leaks collectively reinforce a few emerging realities about the AI landscape.
First, the moat around proprietary AI is thinner than many investors and executives would like to believe. When a developer can rebuild leaked architecture overnight in a different programming language, it suggests that the real value in AI products may not sit where people assume it does. The models and the code are important, but they may be less defensible than the data, the distribution, and the speed of iteration that surround them.
Second, the open-source AI ecosystem is a force that grows stronger with every leak and every intentional release. The original LLaMA leak helped catalyze a movement that has since produced models competitive with the best proprietary offerings. By early 2026, open-weight models from multiple labs were matching or exceeding proprietary systems on standard benchmarks, at a fraction of the cost. Each leak adds fuel to an already roaring fire.
Third, safety and security conversations need to catch up with the pace of deployment. If the detailed inner workings of AI safety systems can leak through a packaging error, the industry needs to think harder about defense in depth. Security through obscurity has never been a reliable strategy, and AI tools with millions of users are high-value targets for anyone looking for weaknesses to exploit.
Fourth, the Meta AI agent incident signals that leaks are no longer exclusively a human problem. As organizations hand AI agents valid credentials and broad system access, they are creating a new category of insider risk. These agents can retrieve, surface, and redistribute sensitive information at machine speed, and they do not pause to consider whether their actions violate access policies. Governing AI agents with the same rigor applied to human employees, including role-based access controls enforced at the output level and mandatory human review before sensitive actions are taken, is quickly becoming a requirement rather than a best practice.
The AI industry is unlikely to stop leaking. The combination of rapid development cycles, massive codebases, public distribution channels, and intense competitive pressure creates an environment where accidental exposure is almost inevitable. The question is not whether more leaks will happen, but how companies and the broader ecosystem will respond when they do.
For AI companies, the lesson is that anything shipped externally should be treated as potentially public. For researchers and developers, each leak offers a window into how the most advanced AI systems actually work under the hood. And for everyone else, these events are a reminder that the AI tools shaping our world are built by humans, distributed through human systems, and subject to very human mistakes.
The walls around AI are not as high as they look from the outside. And every time one cracks, the landscape shifts a little further toward openness, whether anyone planned for it or not.
If your company is utilizing AI tools (which we do recommend) the first thing you need to address is guidelines for how it accesses your data, just like with Microsoft, you should consider any data you share with AI and within your company from a “shared responsibility” perspective. This means that your most sensitive data (think passwords, payment information etc) is kept under lock and key and the data you do wish to give AI access to has been properly evaluated and sanitized. Data hygiene should be the first step to any AI readiness plan and Valley Techlogic can assist with that planning. Learn more today with a consultation.
AI (Artificial Intelligence) continues to proliferate modern workspaces, with some companies leaning heavily into AI investments including up to replacing human workers with an AI equivalent for roles such as customer service.
One company, Klarna, is facing some pushback from investors for just such a strategy. Last year, Klarna which is known for it’s “buy now, pay later” financing for consumer purchasing, replaced 700 workers in favor of an AI solution for customer support. Now, their valuation has plummeted from a high of $45.6 billion in 2021 to $6.7 billion in 2025.
At the heart of it is customer complaints of lower customer service satisfaction which has caused the company to pivot on their “AI First” strategy with their CEO Sebastian Siemiatkowski stating recently “Really investing in the quality of the human support is the way of the future for us.”
What does this mean for medium and small businesses looking at their own strategizing when it comes to artificial intelligence? Testing the waters and applying it in moderation to start is key to a successful AI roll out.
While it may seem tempting to just go all in, especially if savings are on the table in terms of labor costs, the current iterations of artificial intelligence are not ready to be deployed without human oversight and intervention in our opinion. Rather than expecting AI to take over and replace human activities, it’s best to look at how you can use AI as a tool to do more.
Here are three ways we recommend using AI to get the most out of your workday:
Automating Repetitive Tasks
AI can handle time-consuming activities like data entry, scheduling, and basic customer queries. This frees up employees to focus on higher-value, strategic work that requires human judgment and creativity.
Enhancing Decision-Making
AI-powered analytics tools can process vast amounts of data quickly and provide actionable insights. This helps employees make faster, more informed decisions without spending hours combing through spreadsheets or reports.
Personalizing Training and Support
AI can tailor learning experiences to each employee’s role and pace, recommending relevant skills development or providing just-in-time answers through intelligent chatbots. This boosts engagement and accelerates on-the-job learning
If developing an AI strategy for your business is a priority for you in 2025, Valley Techlogic can help. We make it a priority to stay at the forefront of emerging technologies and help our clients access continuous improvements in the tech space to meet their goals. Reach out today for a consultation.
Looking for more to read? We suggest these other articles from our site.
AI or Artificial Intelligence is becoming more and more common place in our daily lives, including in our places of work. You may even be using it daily without realizing it, most search engines for example have an AI response to queries baked in at the top of the page and if that’s the farthest you look then all of your searches are currently being powered by AI.
Which brings us to the topic of today’s article, AI in general is powered by give and take. The models collect our data and turn that data into answers, it’s a common misconception that AI is producing the answers all by itself. Machine learning operates on a rule of 10, basically for every query you need 10 ways to respond, and those responses are collected by unfathomable amounts of data fed into it. Think of the breadth of knowledge an AI program like ChatGPT seems to have and you can begin to see that it would take a lot of data for it to provide to answers to millions of different questions it’s asked each day.
So that data comes from you, and me, and everyone who’s ever interacted on the internet in a meaningful way. It’s not necessarily a bad thing, after all humanity tends to accomplish its greatest achievements when we all work in unison towards a goal. Although the way that the data is collected and how to approach things like copyright are still being determined.
So, with all that said you might be wondering, what’s the problem? What should I be worried about when using AI in my workplace? As a technology company, we believe in using the tools available to streamline and strengthen our productivity, but we have determined that companies should be aware of these three things when using a burgeoning technology like AI in their workplace:
Data Risks: As we hinted at above, AI systems tend to syphon as much information as they can to strengthen their machine learning algorithms. This includes potentially sensitive data. Any AI strategy should include how to protect and segment data you don’t want leaked to the outside world.
Errors and Reliability: There are risks to trusting AI completely when looking for answers, AI data sets are fed by a wide range of sources and not all of them are trustworthy. You should always vet any answers you receive, especially if the question you’re asking is an important one.
Bias, Discrimination and Transparency: Most of the AI tools currently on the market are being created by private companies and the processes used are hidden from outside view, so we should keep in mind that it’s possible the answers we’re receiving have been manipulated to reflect a certain outcome. Again, always vet the answers you receive from AI.
Now that we’ve touched on the things to look out for, what are three things that you can safely use AI for in your workplace?
Use a local AI model: Most people are not aware you can actually have a local in-house AI model, these may be more limited in scope but will not present the security risk of public facing AI and can be built on your own data.
Automating repetitive tasks: Certain tasks won’t carry any risk of data exposure, such as scheduling or creating reports without PII (Personal Identifying Information).
Use it to interact with customers: One of the best use cases of AI currently for businesses is automated chatbots, chatbots can be available 24 hours a day and field simple questions and answers which free up your staff for other activities.
If you’re looking for the most practical and safest way to begin using AI in your business, Valley Techlogic can help. We are experienced in creating customized technology solutions for our clients and can advise on the way to implement an AI plan that doesn’t compromise on cybersecurity best practices. Reach out today for a consultation.
Looking for more to read? We suggest these other articles from our site.
The race for domination continues to heat up at China’s AI model “DeepSeek” enters the fray, just days after newly inaugurated President Trump announced his plans to invest 500 billion in AI infrastructure during the course of his term.
Established as a startup under the same umbrella as the quantitive hedge fund High-Flyer, which is primarily owned by AI enthusiast Liang WenFeng (who built his fortune during the 2007-2008 financial crisis), little has been verified about how DeepSeek came to be.
That has not stopped endless speculation since it’s launch was announced, including how much of it is modeled after existing AI models such OpenAI’s ubiquitous model, ChatGPT.
Also being questioned is how the chips it was trained on were sourced, chip restrictions were placed in on China in 2019 which continued under President Biden specifically to curtail China’s ability to access infrastructure used in the advancement of AI technology. This restriction not only covered the chips themselves, but the technology used to manufacture them.
According to Liang, he sourced the the 10,000 Nvidia A100 GPUs prior to the federally imposed ban.
At present time the founders of DeepSeek are indicating that their goal is to continue the research and advancement of AI infrastructure with their model and not seek commercialization. To back these claims, you can currently download the first series of their model for free open source whether you’re a researcher or a commercial user.
It should also be noted that DeepSeek has an updated data set as compared to ChatGPT, which is currently capped to data from 2023, what this means is its most recent data is from 2023 and before and anything that occurred in 2024 and beyond would not be available so if you were to example ask ChatGPT “Who won the 2024 Presidential Election?” it may not give you a correct answer.
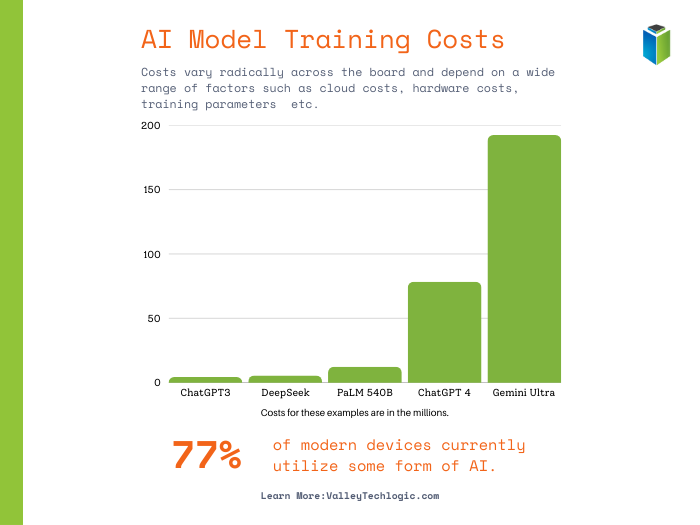
There have also been claims that DeepSeek is much cheaper to train, although training costs for existing AI models are largely inflated. These costs are based on the cost of cloud computing rental prices, which have a wide range of variance.
AI and cloud computing are both worthy investments for businesses looking to strategically position themselves for technology growth in 2025 and beyond, and Valley Techlogic is at the forefront of utilizing these technologies.
Whether it be initializing AI tools like Microsoft’s Co-Pilot in your business or migrating more of your operations to the cloud to reduce overhead spending on physical hardware, we’ve got you covered. Reach out today for a consultation and learn how you can catapult your business forward with technology advancements through Valley Techlogic.
Looking for more to read? We suggest these other articles from our site.
We use cookies to improve your experience on our site. By using our site, you consent to cookies.
Cookie Preferences
Manage your cookie preferences below:
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
Bing, powered by Microsoft, is a search engine providing web, image, video, and map search capabilities.
Name
Description
Duration
_uetvid
1 Year
KievRPSAuth
Helps to authenticate you when you sign in with your Microsoft account.
5 years
MSNRPSAuth
Helps to authenticate you when you sign in with your Microsoft account.
5 years
MSPAuth
Helps to authenticate you when you sign in with your Microsoft account.
5 years
PPAuth
Helps to authenticate you when you sign in with your Microsoft account.
5 years
CC
Contains a country code as determined from your IP address.
1 year
ANONCHK
Used to store session ID for a users session to ensure that clicks from adverts on the Bing search engine are verified for reporting purposes and for personalisation
10 minutes
ANON
Contains the A, a unique identifier derived from your Microsoft account, which is used for advertising, personalization, and operational purposes. It is also used to preserve your choice to opt out of interest-based advertising from Microsoft if you have chosen to associate the opt-out with your Microsoft account.
1 year
_uetvid
This is a cookie utilised by Microsoft Bing Ads and is a tracking cookie. It allows us to engage with a user that has previously visited our website.
16 days
_uetsid
This cookie is used by Bing to determine what ads should be shown that may be relevant to the end user perusing the site.
30 minutes
MSFPC
Identifies unique web browsers visiting Microsoft sites. These cookies are used for advertising, site analytics, and other operational purposes.
1 year
ACH01
Maintains information about which ad and where the user clicked on the ad.
End of session (browser)
x-ms-gateway-slice
Identifies a gateway for load balancing.
End of session (browser)
ToptOut
Records your decision not to receive interest-based advertising delivered by Microsoft.
1 year
AADSSO
Microsoft Microsoft Online Authentication Cookie
End of session (browser)
brcap
Microsoft Microsoft Online Authentication Cookie
1 year
MUID
Identifies unique web browsers visiting Microsoft sites. These cookies are used for advertising, site analytics, and other operational purposes.
1 year
MUIDB
Identifies unique web browsers visiting Microsoft sites. These cookies are used for advertising, site analytics, and other operational purposes.
1 year
MC1
Identifies unique web browsers visiting Microsoft sites. These cookies are used for advertising, site analytics, and other operational purposes.
1 year
MR
Used to collect information for analytics purposes.
6 months
MH
Appears on co-branded sites where Microsoft is partnering with an advertiser. This cookie identifies the advertiser, so the right ad is selected.
End of session (browser)
MS0
Identifies a specific session.
End of session (browser)
_UR
This cookie is used by the Bing advertising network for advertising tracking purposes.
1 year
NAP
Contains an encrypted version of your country, postal code, age, gender, language and occupation, if known, based on your Microsoft account profile.
1 year
childinfo
Contains information that Microsoft account uses within its pages in relation to child accounts.
5 years
kcdob
Contains information that Microsoft account uses within its pages in relation to child accounts.
5 years
kcrelid
Contains information that Microsoft account uses within its pages in relation to child accounts.
5 years
kcru
Contains information that Microsoft account uses within its pages in relation to child accounts.
5 years
pcfm
Contains information that Microsoft account uses within its pages in relation to child accounts.
5 years
ACLUSR
This cookie is used for advertisement tracking purposes.
1 year
_HPVN
Analysis service that connects data from the Bing advertising network with actions performed on the website.
1 year
MC0
Detects whether cookies are enabled in the browser.
End of session (browser)
_RwBf
This cookie helps us to track the effectiveness of advertising campaigns on the Bing advertising network.
1 year
MSPProf
Helps to authenticate you when you sign in with your Microsoft account.
5 years
SRM_B
Collected user data is specifically adapted to the user or device. The usercan also be followed outside of the loaded website, creating a picture of the visitor's behavior.
1 year
WLSSC
Helps to authenticate you when you sign in with your Microsoft account.
5 years
MSPTC
This cookie registers data on the visitor. The information is used to optimize advertisement relevance.
1 year
ACL
This cookie is used for advertisement tracking purposes.
3 months
BFB
This cookie is used for advertisement tracking purposes.
1 year
BFBUSR
This cookie is used for advertisement tracking purposes.
1 year
BCP
This cookie is used for advertisement tracking purposes.
1 year
OIDR
This cookie is used by the Bing advertising network for advertising tracking purposes.
3 months
OIDI
This cookie is used by the Bing advertising network for advertising tracking purposes.
3 months
OID
This cookie is used by the Bing advertising network for advertising tracking purposes.
3 months
Hotjar is a powerful analytics tool that helps you understand user behavior through heatmaps and session recordings.
Name
Description
Duration
_hjSessionUser_1849187
1 Year
_hjShownFeedbackMessage
This cookie is set when a visitor minimizes or completes Incoming Feedback. This is done so that the Incoming Feedback will load as minimized immediately if they navigate to another page where it is set to show.
365 days
_hjDonePolls
Hotjar cookie. This cookie is set once a visitor completes a poll using the Feedback Poll widget. It is used to ensure that the same poll does not re-appear if it has already been filled in.
365 days
_hjMinimizedPolls
Hotjar cookie. This cookie is set once a visitor minimizes a Feedback Poll widget. It is used to ensure that the widget stays minimizes when the visitor navigates through your site.
365 days
_hjDoneTestersWidgets
Hotjar cookie. This cookie is set once a visitor submits their information in the Recruit User Testers widget. It is used to ensure that the same form does not re-appear if it has already been filled in.
365 days
_hjMinimizedTestersWidgets
Hotjar cookie. This cookie is set once a visitor minimizes a Recruit User Testers widget. It is used to ensure that the widget stays minimizes when the visitor navigates through your site.
365 days
_hjHasCachedUserAttributes
This cookie sets when a user first lands on a page. Persists the Hotjar User ID which is unique to that site. Hotjar does not track users across different sites. Ensures data from subsequent visits to the same site are attributed to the same user ID.
365 days
_hjCookieTest
This cookie checks to see if the Hotjar Tracking Code can use cookies. If it can, a value of 1 is set.
Session
_hjUserAttributesHash
User Attributes sent through the Hotjar Identify API are cached for the duration of the session in order to know when an attribute has changed and needs to be updated.
session
_hjCachedUserAttributes
This cookie stores User Attributes which are sent through the Hotjar Identify API, whenever the user is not in the sample. These attributes will only be saved if the user interacts with a Hotjar Feedback tool.
session
_hjLocalStorageTest
This cookie is used to check if the Hotjar Tracking Script can use local storage. If it can, a value of 1 is set in this cookie. The data stored in_hjLocalStorageTest has no expiration time, but it is deleted immediately after creating it so the expected storage time is under 100ms.
-
_hjid
Hotjar cookie. This cookie is set when the customer first lands on a page with the Hotjar script. It is used to persist the random user ID, unique to that site on the browser. This ensures that behavior in subsequent visits to the same site will be attributed to the same user ID.
365 days
hj_visitor
hotjar uses cookies to enhance the user’s experience on our website, for example to complete forms, navigating the site, and identify returning users and offer related content. Users can control the use of cookies at the individual browser level.
Session
_hjIncludedInSample
Hotjar cookie. This session cookie is set to let Hotjar know whether that visitor is included in the sample which is used to generate funnels.
365 days
_hjClosedSurveyInvites
Hotjar cookie. This cookie is set once a visitor interacts with a Survey invitation modal popup. It is used to ensure that the same invite does not re-appear if it has already been shown.
365 days
_hjSessionRejected
If present, this cookie will be set to 1 for the duration of a user’s session, if Hotjar rejected the session from connecting to our WebSocket due to server overload. This cookie is only applied in extremely rare situations to prevent severe performance issues.
session
_hjIncludedInSessionSample
This cookie is set to let Hotjar know whether that visitor is included in the data sampling defined by your site's daily session limit
30 minutes
_hjSession_
A cookie that holds the current session data. This ensues that subsequent requests within the session window will be attributed to the same Hotjar session.
30 minutes
_hjSessionUser_
Hotjar cookie that is set when a user first lands on a page with the Hotjar script. It is used to persist the Hotjar User ID, unique to that site on the browser. This ensures that behavior in subsequent visits to the same site will be attributed to the same user ID.
365 days
_hjSessionTooLarge
Causes Hotjar to stop collecting data if a session becomes too large. This is determined automatically by a signal from the WebSocket server if the session size exceeds the limit.
session
_hjSessionResumed
A cookie that is set when a session/recording is reconnected to Hotjar servers after a break in connection.
session
hjViewportId
This cookie stores user viewport details such as size and dimensions.
Session
_hjSessionStorageTest
This cookie checks if the Hotjar Tracking Code can use Session Storage. If it can, a value of 1 is set.
Session
_hjTLDTest
When the Hotjar script executes we try to determine the most generic cookie path we should use, instead of the page hostname. This is done so that cookies can be shared across subdomains (where applicable). To determine this, we try to store the _hjTLDTest cookie for different URL substring alternatives until it fails. After this check, the cookie is removed.
session
_hjIncludedInPageviewSample
This cookie is set to let Hotjar know whether that visitor is included in the data sampling defined by your site's page view limit.
30 minutes
_hjFirstSeen
The cookie is set so Hotjar can track the beginning of the user's journey for a total session count. It does not contain any identifiable information.
30 minutes
_hjAbsoluteSessionInProgress
The cookie is set so Hotjar can track the beginning of the user's journey for a total session count. It does not contain any identifiable information.
30 minutes
_hjptid
This cookie is set for logged in users of Hotjar, who have Admin Team Member permissions. It is used during pricing experiments to show the Admin consistent pricing across the site.
session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gat
Used to monitor number of Google Analytics server requests when using Google Tag Manager
1 minute
_gac_
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utma
ID used to identify users and sessions
2 years after last activity
Hotjar is a powerful analytics tool that helps you understand user behavior through heatmaps and session recordings.
Name
Description
Duration
_hjShownFeedbackMessage
This cookie is set when a visitor minimizes or completes Incoming Feedback. This is done so that the Incoming Feedback will load as minimized immediately if they navigate to another page where it is set to show.
365 days
_hjMinimizedTestersWidgets
Hotjar cookie. This cookie is set once a visitor minimizes a Recruit User Testers widget. It is used to ensure that the widget stays minimizes when the visitor navigates through your site.
365 days
_hjDoneTestersWidgets
Hotjar cookie. This cookie is set once a visitor submits their information in the Recruit User Testers widget. It is used to ensure that the same form does not re-appear if it has already been filled in.
365 days
_hjMinimizedPolls
Hotjar cookie. This cookie is set once a visitor minimizes a Feedback Poll widget. It is used to ensure that the widget stays minimizes when the visitor navigates through your site.
365 days
_hjDonePolls
Hotjar cookie. This cookie is set once a visitor completes a poll using the Feedback Poll widget. It is used to ensure that the same poll does not re-appear if it has already been filled in.
365 days
_hjClosedSurveyInvites
Hotjar cookie. This cookie is set once a visitor interacts with a Survey invitation modal popup. It is used to ensure that the same invite does not re-appear if it has already been shown.
365 days
_hjIncludedInSample
Hotjar cookie. This session cookie is set to let Hotjar know whether that visitor is included in the sample which is used to generate funnels.
365 days
hj_visitor
hotjar uses cookies to enhance the user’s experience on our website, for example to complete forms, navigating the site, and identify returning users and offer related content. Users can control the use of cookies at the individual browser level.
Session
_hjid
Hotjar cookie. This cookie is set when the customer first lands on a page with the Hotjar script. It is used to persist the random user ID, unique to that site on the browser. This ensures that behavior in subsequent visits to the same site will be attributed to the same user ID.
365 days
_hjHasCachedUserAttributes
This cookie sets when a user first lands on a page. Persists the Hotjar User ID which is unique to that site. Hotjar does not track users across different sites. Ensures data from subsequent visits to the same site are attributed to the same user ID.
365 days
_hjSessionResumed
A cookie that is set when a session/recording is reconnected to Hotjar servers after a break in connection.
session
hjViewportId
This cookie stores user viewport details such as size and dimensions.
Session
_hjSessionStorageTest
This cookie checks if the Hotjar Tracking Code can use Session Storage. If it can, a value of 1 is set.
Session
_hjTLDTest
When the Hotjar script executes we try to determine the most generic cookie path we should use, instead of the page hostname. This is done so that cookies can be shared across subdomains (where applicable). To determine this, we try to store the _hjTLDTest cookie for different URL substring alternatives until it fails. After this check, the cookie is removed.
session
_hjCookieTest
This cookie checks to see if the Hotjar Tracking Code can use cookies. If it can, a value of 1 is set.
Session
_hjUserAttributesHash
User Attributes sent through the Hotjar Identify API are cached for the duration of the session in order to know when an attribute has changed and needs to be updated.
session
_hjCachedUserAttributes
This cookie stores User Attributes which are sent through the Hotjar Identify API, whenever the user is not in the sample. These attributes will only be saved if the user interacts with a Hotjar Feedback tool.
session
_hjLocalStorageTest
This cookie is used to check if the Hotjar Tracking Script can use local storage. If it can, a value of 1 is set in this cookie. The data stored in_hjLocalStorageTest has no expiration time, but it is deleted immediately after creating it so the expected storage time is under 100ms.
-
_hjSessionTooLarge
Causes Hotjar to stop collecting data if a session becomes too large. This is determined automatically by a signal from the WebSocket server if the session size exceeds the limit.
session
_hjSessionRejected
If present, this cookie will be set to 1 for the duration of a user’s session, if Hotjar rejected the session from connecting to our WebSocket due to server overload. This cookie is only applied in extremely rare situations to prevent severe performance issues.
session
_hjSessionUser_
Hotjar cookie that is set when a user first lands on a page with the Hotjar script. It is used to persist the Hotjar User ID, unique to that site on the browser. This ensures that behavior in subsequent visits to the same site will be attributed to the same user ID.
365 days
_hjSession_
A cookie that holds the current session data. This ensues that subsequent requests within the session window will be attributed to the same Hotjar session.
30 minutes
_hjIncludedInSessionSample
This cookie is set to let Hotjar know whether that visitor is included in the data sampling defined by your site's daily session limit
30 minutes
_hjIncludedInPageviewSample
This cookie is set to let Hotjar know whether that visitor is included in the data sampling defined by your site's page view limit.
30 minutes
_hjFirstSeen
The cookie is set so Hotjar can track the beginning of the user's journey for a total session count. It does not contain any identifiable information.
30 minutes
_hjAbsoluteSessionInProgress
The cookie is set so Hotjar can track the beginning of the user's journey for a total session count. It does not contain any identifiable information.
30 minutes
_hjptid
This cookie is set for logged in users of Hotjar, who have Admin Team Member permissions. It is used during pricing experiments to show the Admin consistent pricing across the site.
session
Marketing cookies are used to follow visitors to websites. The intention is to show ads that are relevant and engaging to the individual user.
Beamer is a presentation software that enables users to create engaging, interactive slideshows for diverse audiences.
Name
Description
Duration
_BEAMER_USER_ID_DjYMYPMX42643
1 Year
_BEAMER_LAST_UPDATE_DjYMYPMX42643
1 Year
_BEAMER_LAST_POST_SHOWN_DjYMYPMX42643
1 year
_BEAMER_FIRST_VISIT_DjYMYPMX42643
-
_BEAMER_FIRST_VISIT_
Set by Beamer (hotjar.com) to store the date of the user’s first interaction with insights.
3000 days
_BEAMER_USER_ID_
Set by Beamer (hotjar.com) to store an internal ID for a user.
300 days
_BEAMER_DATE_
Set by Beamer (hotjar.com). Stores the latest date in which the feed or page was opened.
300 days
_BEAMER_LAST_POST_SHOWN_
Set by Beamer (hotjar.com). Stores the timestamp for the last time the number of unread posts was updated for the user.
300 days
_BEAMER_FILTER_BY_URL_
This cookie is set by Beamer to store whether to apply URL filtering on the feed
20 minutes
Facebook Pixel is a web analytics service that tracks and reports website traffic.